Guide
AI Context: The key to accurate agentic analytics
Imagine you tell a friend, "I need a break." Depending on where you are, that could mean you need a vacation, a five-minute walk, or a literal pause in a workout. A human uses context to know which one you mean, but a computer often takes things at face value.
In data analytics, Large Language Models (LLMs) face this exact same hurdle. If you ask for "last year’s revenue," the AI might see the data but won't know if you mean the calendar year or your company's specific fiscal year. Without "AI Context"—the background information, history, and intent behind a request—the system is just guessing. To get reliable answers from agentic analytics, we have to bridge this gap by giving the AI the same "tribal knowledge" that a human analyst uses to interpret a question and adjust their logic accordingly.
Conversational data analytics
Conversational analytics is central to self-service analytics. Thanks to NLP to SQL and the advancement of generative large language models, users can ask questions in natural language and receive accurate answers without requiring proficiency in SQL, BI tools, or dashboard logic. For example, a sales leader may ask, “Which of our European customers are at risk this quarter?” and immediately explore relevant metrics, segments, and drivers, thereby reducing reliance on analysts to provide answers and build visualizations.
If a sales leader asked an analyst to answer the previous question, the analyst would draw on their experience. They might already know where to find a list of European customers, how the company defines sales quarters, and what “at risk” means. Analysts are implicitly using context to perform their jobs. They have learned the tribal knowledge to understand data sources, perform translations, and apply the business logic.
Why an LLM needs context for agentic analytics
For an LLM, interpreting the same question is impossible without the same context. While an LLM’s internal weights capture general linguistic patterns and dictionary definitions, they do not encompass business-specific definitions of terms such as “customer,” “churn,” or “active user.” For instance, the phrase “top customer” may refer to the customer generating the highest revenue, the most orders, or the strongest margin. Similarly, “sales last year” could refer to either the calendar or fiscal year. Analysts often rely on specialized business terminology, such as “user churn,” “expansion ARR,” or “qualified pipeline,” which seldom correspond directly to column names or metric labels.
Consequence of a lack of AI context
Without the relevant business context, AI for data analytics results in inaccurate, unreliable answers. At best, a user will dismiss the answer and lose trust in the system. At worst, the system will hallucinate a plausible answer, resulting in adverse decisions and actions that may harm the business.
Simply adding an LLM to an existing data warehouse is insufficient for reliable data analytics. Text-to-SQL implementations often fail to achieve human-level accuracy because they lack the necessary context to overcome common challenges. This context includes elements like complex or incomplete database schemas, poor data documentation, ambiguous or conflicting business logic, fragmented business rules, tribal knowledge, and stringent governance requirements. Providing an LLM with this comprehensive context is essential for achieving accurate and trustworthy data analysis - especially when scaling to enterprise complexity and usage.
Types and sources of AI context
Within an enterprise, there are various sources of information that can provide valuable context to an LLM.
Data Context
The most acknowledged and understood context, data context, refers to the structural knowledge that tells the LLM what tables exist, how they join, and what the columns mean. It can include which data sources are reliable and what edge cases cause anomalies.
Without data context, the LLM may invent a path or “hallucinate” rather than flagging the missing context. For example:
User asks: "Show total sales by shipping city."
Hallucinated path: Sales -> Stores -> Cities
With context path: Sales -> Customers -> Addresses -> Cities
Example sources: database schemas, column descriptions and data catalogs
Business Context
The semantic knowledge that captures how the organization defines its metrics, including how definitions have changed over time and how they differ between departments and teams, is known as business context. It can direct the AI to trusted data sources based on the question being asked.
While an LLM can infer some business context and meaning, high-precision SQL generation requires metadata enrichment.
Problem: An LLM might map "Top clients" to a revenue column, while the business logic requires filtering for active_status = 'Gold'.
Solution: Providing the LLM with a JSON-based metadata manifest that includes descriptions, synonyms, and data types for every table and column.
Often, the business context is undocumented tribal knowledge that cannot be addressed by static, rigid semantic layers. It is often best captured as natural language descriptions.
Example sources: formal semantic layers, tribal knowledge and unstructured data
Historical Context
Historical context is the institutional memory of what questions have been asked before. From this, the AI can be shown examples of anomalies investigated, their outcomes, and the basis of the decisions made. It also captures what the AI should not repeat.
Question: "How many active users do we have in EMEA?".
Schema: There is a boolean column
users.is_active.Historical context: The Lead Data Analyst knows that
is_activeis a legacy flag that is no longer accurate. The real definition of an active user—used in all Board-level slides—is "any user who has logged in within the last 30 days AND has a completed transaction."
Example sources: historical queries and existing BI environments
Presentational Context
With presentational context, the LLM's response can be adjusted depending on whether an analyst or an executive is asking a question. This communication judgment enables the LLM to be tailored to the user who asks the question. A user might not be authorized to access certain data, or they may prefer numbers over narrative.
Insights can be framed to help make decisions, for example, by always providing a benchmark by which a trend can be compared.
Example sources: user feedback and governance and security guidelines
Providing AI context to LLMs
You might ask why can’t all the context be provided to an LLM with every query, much like the process of prompt engineering. This approach is constrained by the model’s context window and attention. To explain this, it helps to understand how LLMs process text.
Tokens
Tokens are the fundamental components used for both input and output in a LLM. In the context of natural language processing, tokens often correspond to words, subwords, or individual characters.
Each token stands for a particular word or symbol within the input. The model's generation process involves predicting the most probable token that should follow a given sequence of input tokens.
Context window
The context window defines the total token capacity a model can process in a single interaction. This fixed capacity must accommodate all elements: the system instructions dictating the model's conduct, the ongoing conversation history, any injected external data or documents, and the user's specific query.
Attention
Attention serves as the mechanism by which a language model determines the relevance of tokens to one another. Before generating each new token, the model evaluates it relative to every other token in its context window. This capability allows LLMs to establish connections between concepts across extensive passages of text, but it is also the source of their most significant constraints.
Lost in the Middle
LLMs exhibit an uneven distribution of attention across the context window, a phenomenon often termed the "lost in the middle" problem. Studies have repeatedly demonstrated that tokens situated at the beginning and end of the input receive the most attention, leading to a notable decrease in focus on the middle section. Consequently, placing critical information in the middle of the input can reduce accuracy by over 30% compared to placing it at the start or end.
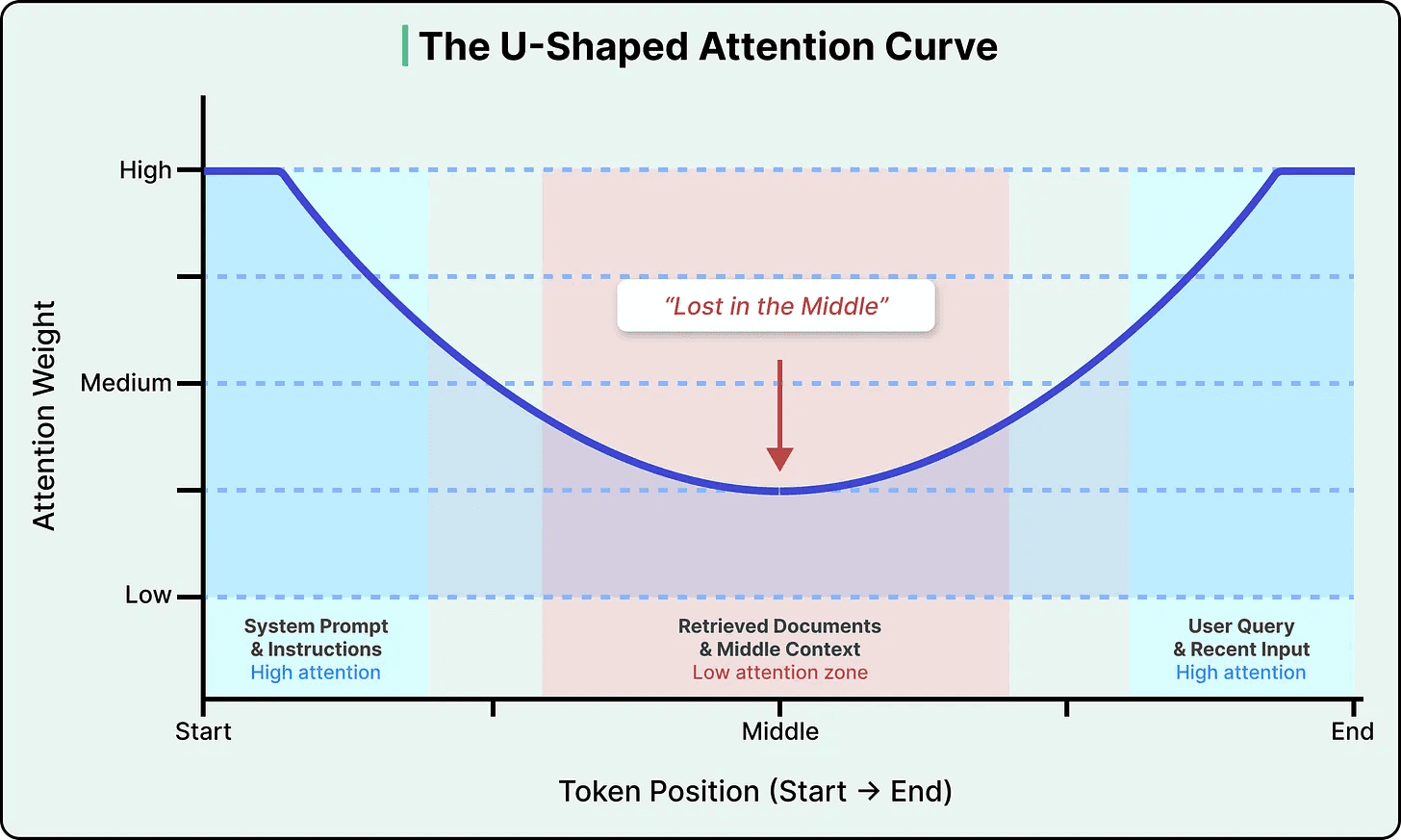
Lost in the Middle limitation of LLMs (Source)
In complex enterprise schemas, providing all Data Definition Language (DDL) statements can exceed token limits or result in 'Lost in the Middle' degradation, where LLMs struggle to recall information located in the middle of lengthy prompts, instead prioritizing content at the beginning and end.
Context engineering
Context engineering is a flexible approach to overcoming the physical limits of tokens and the structural flaws of attention. Rather than treating the prompt as a "dumping ground" for data, context engineering is the strategic process of curating, structuring, and optimizing the information provided within an LLM’s context window.
In an enterprise environment with thousands of tables, providing the entire Data Definition Language (DDL) is impossible. Context engineering uses a "pre-filtering" step to identify only the most relevant tables and columns for a specific query.
AI context layer
The most effective way to provide context to an LLM is through a context layer that translates technical data storage (tables, columns, and keys) into natural language (NL) descriptions. While a model can read a schema, it cannot "know" the intent behind the data without these descriptions.
Shifting to natural language fundamentally changes how the LLM operates by focusing its attention mechanism. Instead of a simple token match. Instead of simply associating the word "sales" with a table named SALES_TBL, the natural language descriptions allow the model to grasp the actual meaning and purpose of that table within the organization.
Business logic is often "tribal". It lives in the heads of analysts rather than in the database code. Static semantic layers (like Looker or dbt) are a start, but natural language descriptions are needed to bridge the context gap. Large enterprises are full of "ghost data". Columns like is_active that are deprecated but still exist. Natural language descriptions serve as a corrective memory.
The context layer also manages how information is distilled based on the user persona. This ensures the model doesn't just provide the right data, but the right narrative – and that your data is governed and secure. This is especially important when granting enterprise access to your data – even more so when you work in a regulated industry.
What are the pitfalls of an enterprise context layer?
While the context layer is undoubtedly a great starting point, it falls over time. That’s because context isn’t static. Each layer of context is in near-constant flux. That’s why you need a system in place to own and maintain context.
In the enterprise setting, it’s not enough to have a single-player system where a context engineer is updating context as it is relayed to them. They need a system that empowers input from every user across the enterprise. So, when a metric definition changes in marketing that impacts a GTM project that the CEO looks at, this context is updated throughout the enterprise system.
Because this influx of context can be hard to manage alone, it’s ideal to have an AI-assisted, human-reviewed context management system. This ensures context is owned, maintained, and consistent – delivering accurate, reliable insights across the organization.
The enterprise-grade AI context solution
WisdomAI’s Adaptive Context Engine learns enterprise context through a staged lifecycle that is designed to balance speed, accuracy, and governance across both cold‑start and steady‑state operations.
How WisdomAI’s Adaptive Context Engine (ACE) works:
Bootstrapping: Establish an initial context baseline from enterprise assets, schemas, sampled data, and historical behavior
Refinement Through Feedback: Improve mappings, defaults, and assumptions using real query usage and explicit human feedback.
Long‑Term Quality Maintenance: Detect conflicts, manage semantic drift, and validate changes before promotion into active use.
This lifecycle allows the system to become useful quickly and empowers data teams to create an adaptively stable, production‑grade understanding of enterprise data as usage grows and requirements evolve.
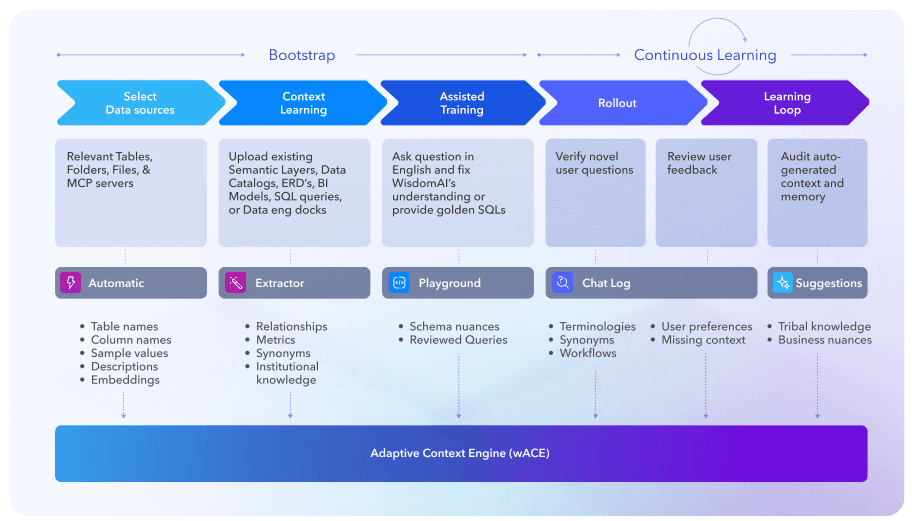
WisdomAI Context Engine (ACE) Context Learning Lifecyle
Once the initial context is established, ACE refines its understanding through usage‑derived signals that reflect how analysts and business users actually work with data. Rather than waiting for a central "Source of Truth" to be perfectly documented — which isn’t technically possible in a changing enterprise environment — ACE allows data analysts and context engineers to codify accuracy through tribal knowledge.
Example of an ACE-Powered Agentic Workflow
Imagine a fintech user asks: "Show me the total 'Gold Tier' revenue for 'Project Phoenix' in Q3."
Standard LLMs lack the organizational knowledge to interpret "Gold Tier" or "Project Phoenix." Here is how ACE orchestrates the resolution across five specialized agents.
Step 1: Entity Extraction Agent
Instead of basic keyword matching, this agent uses ACE to parse the query against a proprietary ontology.
The engine recognizes "Gold Tier" and "Project Phoenix" not as random strings, but as relevant business terms and maps them to their definitions.
Output:
[ "Gold Tier": Entity_Type_Segment, "Project Phoenix": Entity_Type_Project ]
Step 2: Knowledge Retrieval Agent
This agent queries ACE to resolve the definitions.
ACE Support: Rather than just a Vector DB search, which might return "similar" but irrelevant text, ACE translates “Gold Tier” to the subscription levels stored in the database, and “Project Phoenix” is a business alias for a specific product category.
Retrieved Definitions:
Gold Tier:
customers.subscription_level IN (4, 5)Project Phoenix:
products.category_code = 'digital_assets'
Step 3: Schema Mapping Agent
This agent determines the "join path" required to reach the data.
ACE maintains a map of the database schemas, knowing that
customersandsalestables are linked viauser_id, and that "Revenue" is a calculated field defined assum(price * quantity).Action: It constructs a relationship, ensuring the "Project Phoenix" filter is applied to the correct dimension table.
Step 4: SQL Generation Agent
The generator receives the original query enriched by ACE’s outputs. ACE also provides the temporal context. If it’s currently 2026, ACE automatically qualifies "Q3" as 2025-07-01 to 2025-09-30 (the last completed Q3) unless specified otherwise.
The ACE-enriched prompt:
Context:
- Segment 'Gold Tier' -> subscription_level ∈ {4, 5}
- Scope 'Project Phoenix' -> category = 'digital_assets'
- Temporal 'Q3' -> date_range('2025-07-01', '2025-09-30')
Task: Generate executable SQL.
Step 5: Governance & Self-Correction Agent
Before execution, this agent performs a final validation.
The Governance & Trust layer runs the generated SQL through a validator. It checks whether the user has Role-Based Access Control (RBAC) to view "Gold Tier" revenue. If the SQL tries to access a restricted column, ACE blocks or masks the result.
Correction: It might identify that subscription_level is stored as a VARCHAR in production and updates the query to IN ('4', '5') to ensure execution.
By breaking the problem into agents supported by an Adaptive Content Engine, you achieve:
Contextual Fidelity: The SQL generator doesn't "guess"; it uses verified business logic.
Zero-Shot Reliability: The system handles jargon it was never explicitly trained on by looking it up.
Transparent Governance: Every step is auditable, ensuring the AI operates within the enterprise's safety boundaries.
To learn more, read our in-depth whitepaper on the adaptive context engine.
Realize the transformational power of agentic analytics with AI context
The transition from traditional BI to agentic BI represents more than just a change in interface; it is a fundamental shift in how organizations interact with their data. While Large Language Models (LLMs) provide the necessary linguistic engine for this transformation, they remain insufficient on their own due to their inherent probabilistic nature and lack of institutional knowledge.
The Adaptive Context Engine (ACE) solves this challenge by acting as a deterministic middleware infrastructure that monitors, learns, validates, and updates organizational context.
See how ACE can help you bridge the context gap by grounding the LLM with relevant enterprise context. Schedule a demo today.
Summary of key AI context concepts
Concept | Description |
Conversational data analytics | Conversational data analytics enables any user to ask natural language questions about their data. The core technology enabling this is LLMs. |
The "Context Gap" | LLMs lack organization-specific "tribal knowledge." Without definitions for custom metrics (e.g., "Gold Tier" or "Active User"), AI defaults to hallucinations or inaccurate SQL, making raw LLM integration unreliable for enterprise data. |
Types and sources of enterprise context | Accurate AI-based analytics requires four specific types of context: Data (schema and joins), Business (metric definitions and logic), Historical (past queries and legacy flags), and Presentational (user personas and permissions). |
Context Engineering | A strategic approach to managing LLM limits. Rather than "dumping" all data into a prompt, it curates and filters only relevant info to avoid "Lost in the Middle" errors and token overflow. |
AI Context Layer | An architectural layer that stores enterprise context and optimizes it for an LLM. It allows the LLM to understand the intent and purpose of data rather than just matching keywords. |
Adaptive Context Engine | A system that builds and maintains the context layer through a lifecycle of Bootstrapping (initial setup), Refinement (user feedback), and Maintenance (detecting semantic drift), often utilizing specialized AI agents to ensure accuracy. |