
The semantic layer has traditionally been the foundation of self-service BI, serving as a bridge that translates complex data models into business-friendly metrics. However, the rise of generative AI has exposed its limits because today's applications don't just query data; they reason with it.
That's where the context layer comes in. It's an evolution of the semantic layer that empowers LLM-based applications with a deeper understanding of business for today's data, characterized by higher volumes, much faster growth, and increased variety, all without sacrificing the faithfulness of results to the business context.
This article explores the semantic layer and compares it to the context layer in terms of architecture, flexibility, and readiness for generative AI applications in self-service BI.
Summary of key semantic layer vs. context layer concepts
Before proceeding deeper into this topic, here are a few concepts to keep in mind:
Concept | Description |
|---|---|
Semantic layer | The semantic layer was first developed for relational databases to centralize business metrics and definitions, establishing a single source of truth (SSOT) by blending expert domain knowledge with technical database implementation. It consists of a metadata layer, business logic for defining metrics, a security layer for access control, and a query engine to translate and execute user requests, often supported by a caching mechanism. |
Semantic Layer Limitations | Legacy business intelligence (BI) tools were built for descriptive analytics on centralized, premodeled data warehouses, using a traditional semantic layer to provide a single source of truth accessible without SQL. This older architecture is becoming brittle due to the dynamic demands of generative AI, struggling particularly with schema changes where simple column renames break models and facing latency issues due to runtime relationship assessment on relational engines. |
Context Layer | The context layer is an evolution of the semantic layer designed to move beyond simple descriptive analytics by providing generative AI applications with the necessary structured, time-relevant data to support complex tasks. It equips these applications with memory for maintaining conversational state and an ontology derived from knowledge graphs that enables deeper diagnostic and prescriptive analysis by structuring business and entity relationships. Ultimately, this architecture enhances scalability, maintainability, and governance while significantly reducing LLM hallucinations by supplying enriched, traceable context. |
Static sources of context | Static sources of context ground AI in business definitions and structural relationships to enable more accurate analysis. |
Dynamic sources of context | To support interactive analysis, the context layer incorporates dynamic sources of context based on user interaction, which informs the AI about historical behavior and current intent. |
Tools and system context | Tools and system context are built directly into the AI architecture to define its capabilities and constraints for data interaction. This context includes tool and agent definitions, system and meta prompts, and data schema and column descriptions. |
The semantic layer
The semantic layer was initially introduced with the relational database in mind. The idea was that it would maintain a centralized repository of business metrics and definitions, enhancing the ideal of a single source of truth (SSOT). It was a great way to infuse domain knowledge from subject matter experts with the mathematics and code of database analysts, relieving business users of the need to go beyond their technical depth.
How semantic layers are used
Semantic layers can be used within a BI tool; popular BI tools such as Tableau and PowerBI embed semantic modeling within the product. The challenge, however, is that each team ends up creating semantic layers over multiple data silos, by report or dashboard groups. Effectively, metrics and definitions are not all kept in alignment across an organization.
There are also universal/decoupled semantic layers. New products in the market (such as AtScale or Cube) offer a universal semantic layer that can be consumed by multiple tools. The benefit of this approach is that an organization can enforce a single way for users and teams to consume data (via the universal semantic layer) to ensure that they stick to the principles behind a single source of truth.
The architecture of the traditional semantic layer
At the base of the semantic layer is a metadata layer that contains the definitions and relationships among data objects. For a universal semantic layer, you will generally have API connectivity to various source systems such as SQL and REST.
On top of this layer is the business logic that defines metrics and KPIs. At this stage, you will expect to have definitions for fields, measures and dimensions. This is where you specify the granularity of dimensions, such as breaking time down into weeks, days, hours, and minutes.
Supporting this is a security layer to enforce access control, governance, and compliance. This includes logic to handle activities like user authentication, row-level access, and PII management.
Finally, a query engine translates, optimizes and executes SQL queries based on user requests. As an additional performance tool, a caching layer may support the query engine to speed up data retrieval for frequent queries.
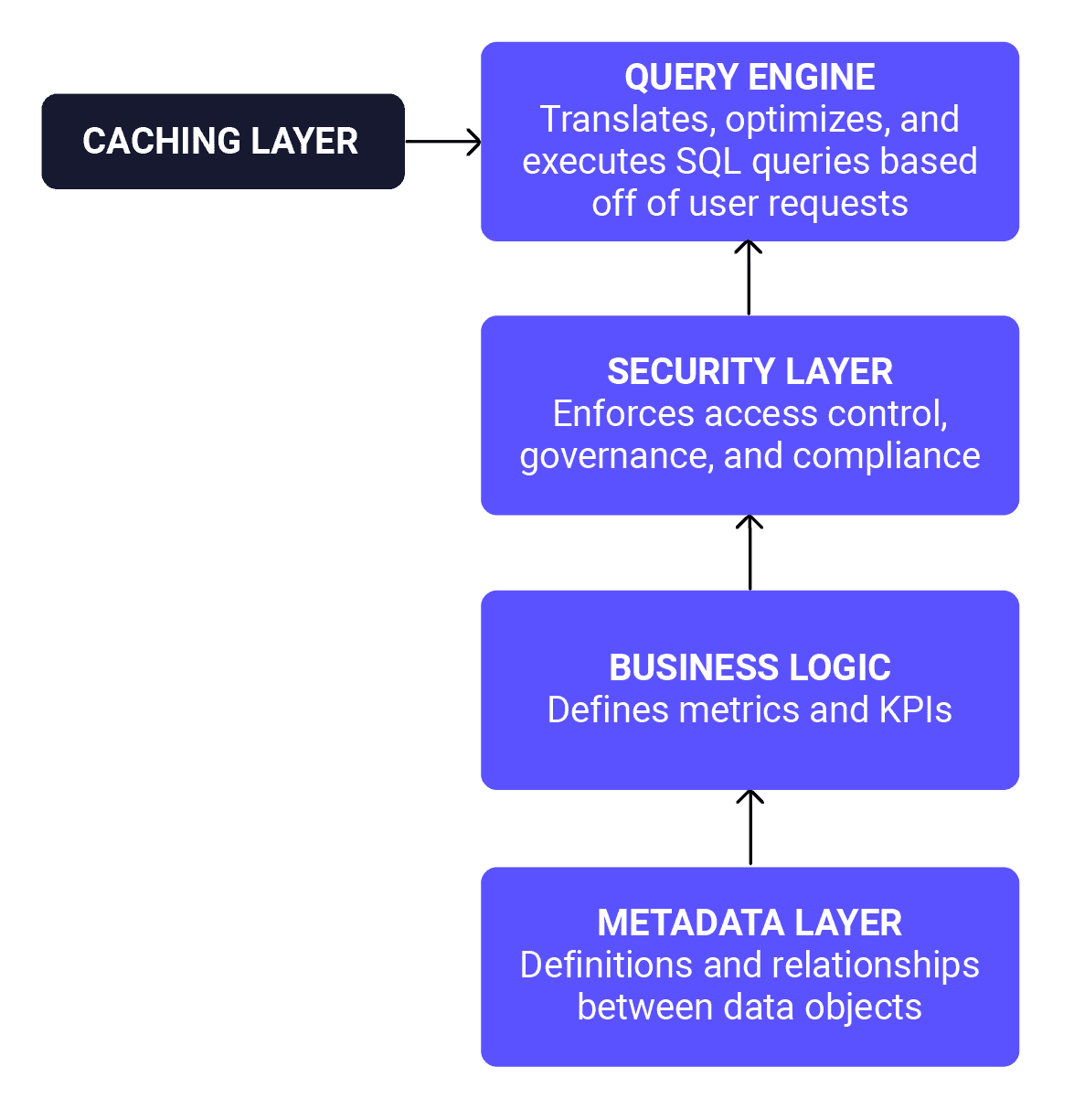
Semantic layer architectural components
The semantic layer's limitations
Legacy BI tools were designed for descriptive analytics to answer the question “what happened?” and were focused on a centralized, premodeled data warehouse. This design made data accessible to business users to support building BI dashboards without needing to write SQL. The semantic layer architecture components were designed to limit ambiguity by providing a single source of truth.
While this architecture worked well in a structured, SQL-centric era, it becomes brittle when faced with the dynamic, unstructured demands of generative AI.
Schema changes
Schema changes are challenging because relational database schemas are inflexible by design. The traditional semantic layer does not richly represent business relationships, entities, and hierarchies beyond just metrics. In this Reddit thread, users complain about how Microsoft Fabric semantic models break when there are changes to the underlying data schema, such as column renaming, resulting in errors such as “missing field.” However, with a context layer, if a column named “player_id” were to change to “athlete_id,” the knowledge graph would be able to remap this entity using its graph ontology, since “athlete” is defined as a subclass of “person.”
Latency
Relational databases experience more latency challenges than non-relational alternatives when data scale multiplies. Semantic layers that depend on relational database engines will suffer query processing limitations, such as time delays when joining tables with millions of records, because relationships are assessed during execution time.
The context layer cuts down on these delays with joins since the relationships in a knowledge graph are precomputed, so they are not assessed during query execution time.
Context
Generative AI applications are quite nondeterministic when they don't have sufficient context. LLMs need three types of context for text-to-SQL:
Database schema context: this provides table and column names, relationships between tables and columns, and data types.
Business context: a user querying with natural language will use business jargon with specific definitions.
Usage context: historical queries and past user interactions provide examples of successful queries.
The traditional semantic layer isn't designed to support these context needs. For example, Cortex Analyst, as currently designed, does not answer questions from previous results. The documentation notes that Cortex Analyst is great at generating SQL to query a database but doesn't explain results, such as providing business insights.
Enter the context layer
The context layer is what you get when you evolve the semantic layer into a tool that is expected to do more than descriptive analytics. Many text-to-SQL applications do very well with generating syntactically correct SQL statements from natural language requests. However, several of them fall short when required to interpret query results in a way that is relevant for diagnostic or even prescriptive analytics.
Unlike a traditional semantic layer, the context layer can handle unstructured data in documents, tickets, logs, policies, social media interactions, and more, being that they are not always available in enterprise warehouses. Traditional semantic layers are only designed for structured data sources. Building semantics for unstructured data, semi-structured data, SaaS data sources, or MCP servers is not possible. All of these form rich information for an LLM, without which LLM responses may lack depth of accuracy.
The context layer provides a generative AI application with structured, time-relevant data to support an active task. Knowledge graphs continuously ingest information into the context layer and use it.
The context layer provides generative AI systems with the following essentials:
Memory: A generative AI application for BI can manage conversational state better with the context layer. This is very important for requests where you need the application to compare, interpret, forecast, or recommend.
Ontology: By using knowledge graphs to keep track of business relationships, entity relationships, hierarchies and other unstructured data, the context layer provides stronger support for structured reasoning by LLMs. This is what empowers such an application to do diagnostic and prescriptive analysis.
Scalability and maintainability: Since lineage, ontology, and memory are better handled in the context layer, it is much easier to integrate evolving business definitions and growing data.Reduced hallucinations: With enriched context and the tracking of rapid changes, it is less likely for an LLM to make up metrics or responses.
Governance: With better ontology, even unstructured data is better discovered, with clear paths that aid auditing. The context layer helps the right people get the right data access regardless of the data type.
Key differences between the semantic layer and context layer
While the context layer builds upon the semantic layer and thus can be seen as an enhanced version, it is not simply a rebrand: It provides key improvements. Here is a summary of key differences between the semantic layer and context layer to set the tone.
Capability | Semantic Layer | Context Layer |
|---|---|---|
Primary function | Translate data models into business logic | Provide AI systems with contextual, real-time understanding |
Schema flexibility | Low | High |
Handling unstructured data | Limited | Native support |
Real-time context updates | Manual refresh | Continuous ingestion |
LLM integration | Basic (query translation) | Deep (memory and reasoning) |
Performance at scale | Degrades with join and schema changes | Designed for dynamic relationships |
Best suited for | Traditional BI tools | GenAI based applications and agents |
The WisdomAI Context Layer
Next-generation AI systems for data analysis use context layers to teach LLMs about your business data. WisdomAI’s Context Layer learns from unstructured sources and usage patterns. For example, if the semantic layer defines that “customer” in the CRM corresponds to “tbl_client” in the database, the Context Layer might also learn from support tickets that “client” and “customer” are used interchangeably and from a wiki page that “VIP” is a special type of customer. It then knows that a “VIP customer churn” question involves filtering customers with a VIP flag, even if the raw schema uses different terminology.
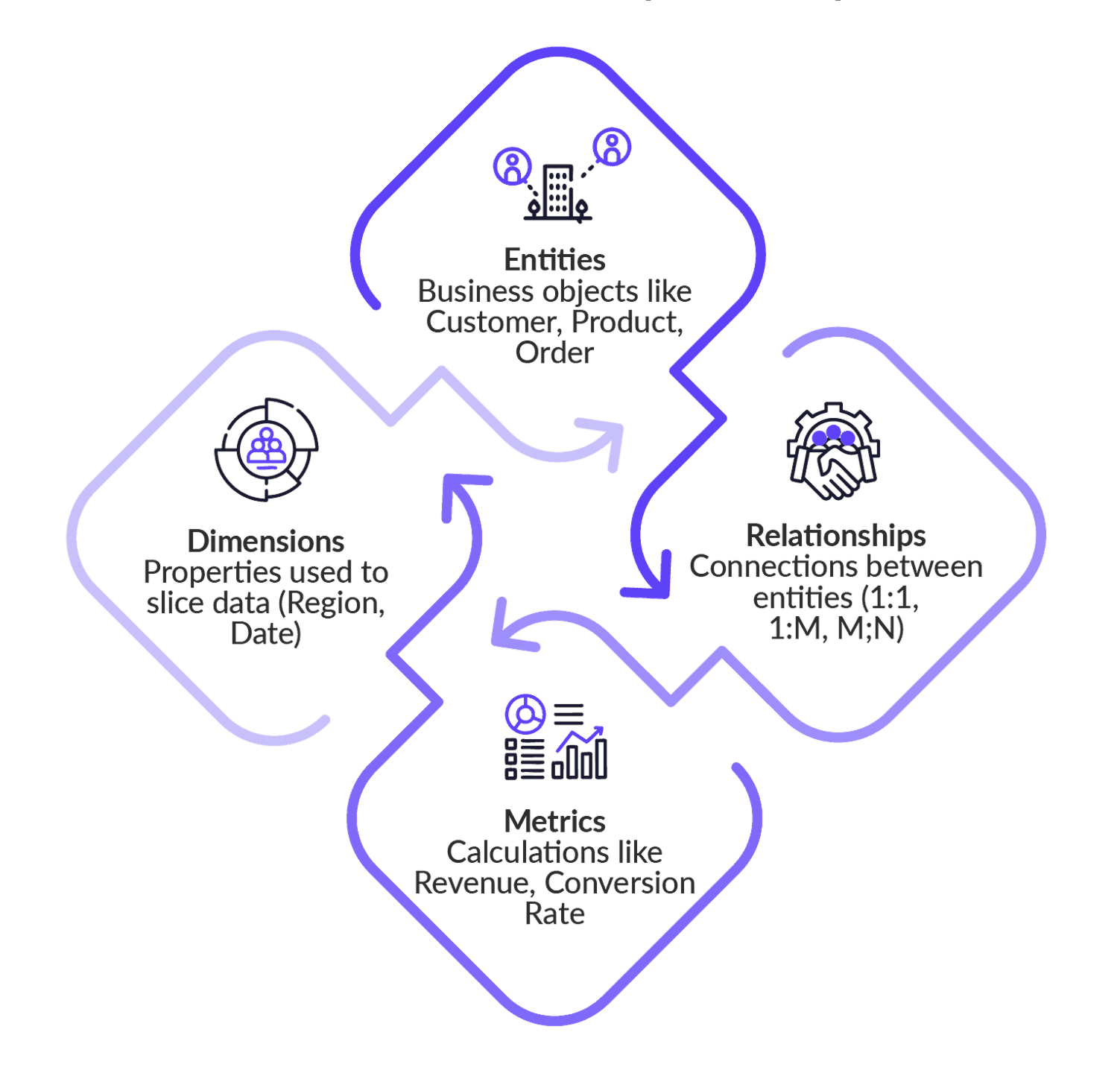
WisdomAI Context Layer components (source)
Sources of context for the Context Layer
The context layer continuously learns from multiple static and dynamic sources to enrich its understanding of data relationships, user intent, and business meaning.
Static sources
These methods provide AI with definitions and structural relationships regarding data sources.
Formal semantic layers
These provide a unified, business-friendly view of data, defining standardized metrics, KPIs, and business terminology. They translate complex technical data structures (like table and column names) into a consistent business language (e.g., defining what an “active customer” or “quarterly revenue” means).
The Open Semantic Interchange (OSI) is an initiative to create a common, vendor-neutral standard for semantic models. Inconsistent data definitions from different sources is a blocker to AI scalability.
AI benefit: Minimizes AI “hallucinations” by grounding responses in governed business logic.
Data catalogs
These centralized repositories document and manage metadata, including data source, lineage, quality scores, ownership, and definitions.
AI benefit: Enables the AI to discover the right data for a query, assess its trustworthiness, and understand its provenance (where it came from and how it was processed).
Data relationships
Relationships explicitly model the connections, dependencies, and hierarchies between different data entities (e.g., knowing that a “customer” entity relates to “orders” and “products”).
AI benefit: Allows the AI system to reason over data structures and join data sources.
Data governance
This area encompasses the policies and rules defining data access, security, and classification. Governance rules can be attached as attributes to graph nodes, ensuring the consistent enforcement of access policies.
AI benefit: Provides the system with guardrails
Dynamic sources
These inform the AI about how users interact with the data and what they have asked historically about the connected data sources.
Historical queries
This input type includes analyzing past user questions, successful query patterns (e.g., common join operations), and frequently used dimensions or metrics. Vector embeddings can be used to store these patterns.
AI benefit: Helps the AI predict user intent and optimize queries based on historical examples.
User feedback
Explicit ratings (thumbs up/down) or implicit feedback (how a user modified or continued a session after an AI-generated result) are incorporated using feedback loops, much like reinforcement learning from human feedback (RLHF).
AI benefit: Refines the AI model's behavior over time and corrects misinterpretations.
Session or conversational state
This area covers maintaining a memory of the current interaction, including previous questions, filters applied, and intermediate results. Short-term memory stores like Redis are typically used here. Long-term vector stores can also be used to persist conversational state.
AI benefit: Enables follow-up questions to be answered during a user’s session.
Tools and system context
This context is built into the AI system’s architecture and describes its capabilities and operational constraints to the LLM.
Tool and agent definitions
These definitions provide the AI with access to specific tools (like an SQL query executor, a code interpreter, or a visualization library) along with clear instructions on when and how to use them.
AI benefit: Enables the AI to take action (e.g., run a query, clean data, generate a chart) and dynamically pull in “just-in-time” context from the database or files, rather than needing all data loaded at once.
System and meta prompts
Behind-the-scenes instructions define the AI's role (e.g., “you are an expert financial analyst”), tone, and high-level constraints (e.g., “always use the metric definitions from the semantic layer”).
AI benefit: Sets the foundation for the AI's overall behavior and ensures that all interactions adhere to the required professional and analytical standards.
Data schema and column descriptions
This refers to passing the relevant subset of the database schema (table names, column names, data types, and human-readable descriptions) directly to the LLM.
AI benefit: Allows the AI to correctly map a natural language question (like "show me customer sales") to the underlying database structure.
Last thoughts
Traditional semantic layers are schema-bound, relying on relational joins and static metric definitions. Context layers, however, replace rigid tables with knowledge graphs that dynamically model entities and relationships. This allows AI systems to traverse real-world relationships (e.g., users, products, policies) without the query latency caused by SQL joins.
Putting it all together, here’s what the context layer enables that the traditional semantic layer by itself struggles with:
Coherent multi-turn conversations: You can ask follow-up questions without re-explaining.
Reasoning: The context layer can support complex questions for diagnostic, prescriptive and predictive analytics, not only descriptive analytics.
Reduced hallucinations: Hallucinations are lower due to the availability of up-to-date metrics, clearer ontology, and lineage.
Better handling of vagueness and ambiguity: Efficiency is improved due to context, memory, and relationships that support inference without needing the user to redefine concepts or repeat previous requests.
Integration of unstructured data with structured data: Integration provides value in reasoning use cases.



