Guide
NLP to SQL: History, challenges, and the role of context
There is a well-cited 80/20 rule that says data teams spend about 80 percent of their time preparing data and 20 percent visualizing it. As the business’s data demands grow, there isn’t enough time in the day for your data team to create all the analysis and visualizations that’s requested of them.
Self-service BI promised to solve this problem, but in reality, it just created dashboard sprawl and a growing "trust gap" due to conflicting reports. Then came early Large Language Models (LLMs) and search, which still left business users struggling to find insights. But now, GenAI and agentic analytics are finally offering a viable path forward.
Natural language processing (NLP) to SQL is breaking down the wall between business users and their data, allowing anyone to query a database as easily as they would text a colleague. In this article, we’ll break down how it works, and explore what is really required to deliver trusted, AI-generated answers for your enterprise.
What is text to SQL?
Text to SQL is a type of semantic parsing where the goal is to take a (potentially ambiguous) human question and translate that question to a query over a database. A process that sounds simple until you try to do it reliably at scale and deal with ambiguous meanings.
How NLP to SQL works
At a high-level, text to SQL systems perform the following tasks:
A user asks a question in natural language.
NLP techniques interpret the user’s input and break the question down into meaningful components such as entities, intentions, and context.
Large language models (LLMs) analyze the components to interpret the user’s intent.
The system constructs a syntactically correct SQL statement and optimizes it.
The optimized SQL query is executed against the target database.
The database returns the requested information based on the executed query.
The system translates the raw data into an accessible format, often using natural language or visual representations.
To translate human language into a computer language like SQL, you need to employ linguistic tools like semantic parsing, which replaces a potentially ambiguous natural language statement with an unambiguous description of its meaning.
Real-world example of natural-language ambiguity
Imagine that you are preparing to go on a walk with a friend who asks, “Could you please bring me my coat?” You might look out the window and see that it is snowing; remember that yesterday, you saw them wearing their new black puffer jacket; and recall that on your last walk, they told you they’re glad they didn’t choose their thinner spring jacket. So, you choose to bring them the new warm puffer coat.
In this example, you’re inferring details that are in the context of the question but not the question itself. You are reasoning under ambiguity, a process that we as humans do constantly, often unconsciously. You are making a broad, general request (“bring me my coat”) into a specific, actionable statement (“bring me the black puffer jacket you saw me wearing yesterday”). This is why providing sufficient context for text to SQL is required to produce accurate SQL statements.
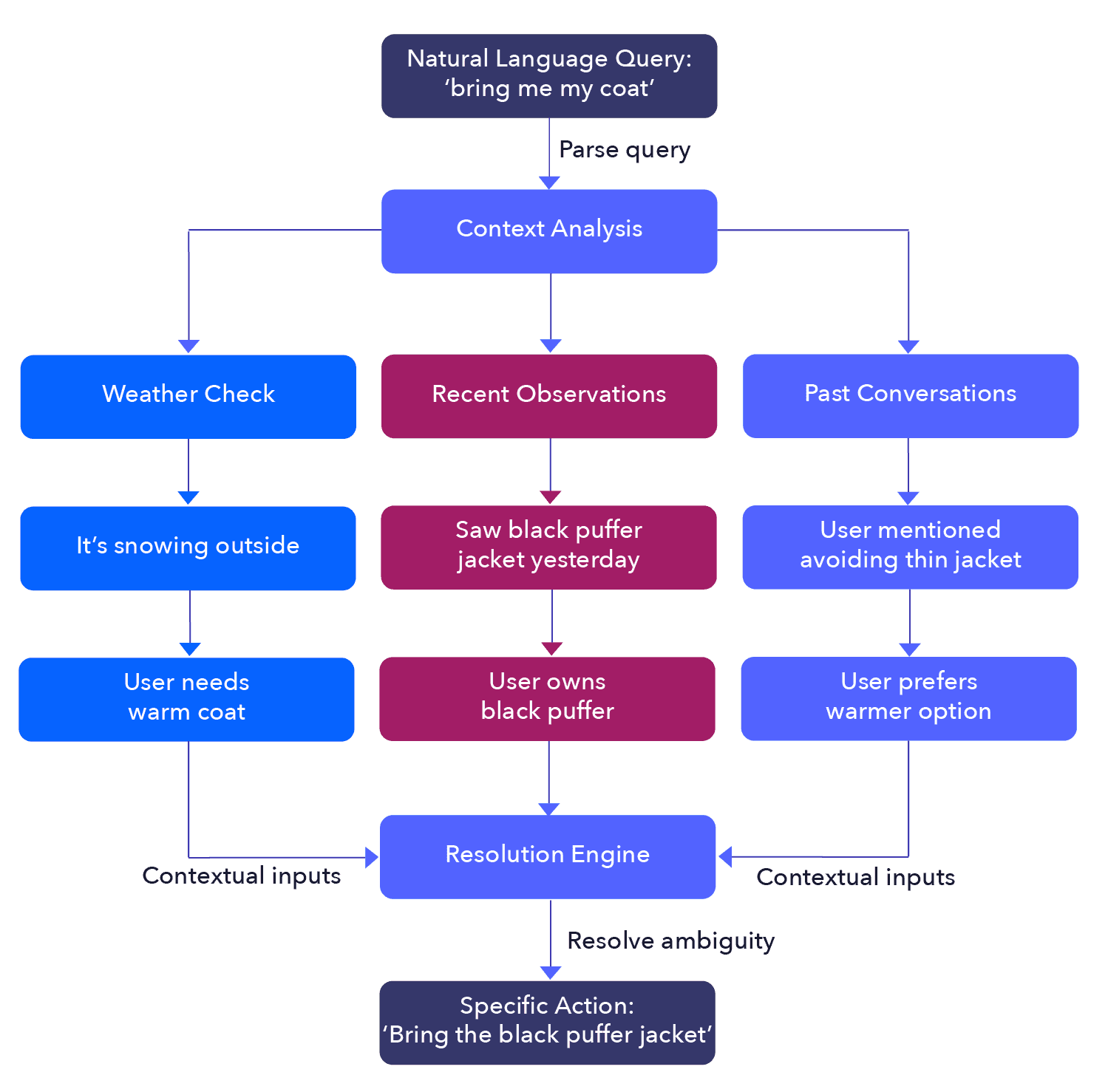
NLP to SQL example
History of NLP-to-SQL systems
Since the advent of computer technology, people have built systems to allow users to better communicate with machines.
Think of the early interfaces, where users needed to write commands into a computer in order to run programs and initiate processing. Then came browsers and more advanced interfaces that allowed non-technical users to use keyword search and interact with the world wide web. These initial advancements paved the way to modern-day text-to-SQL systems.
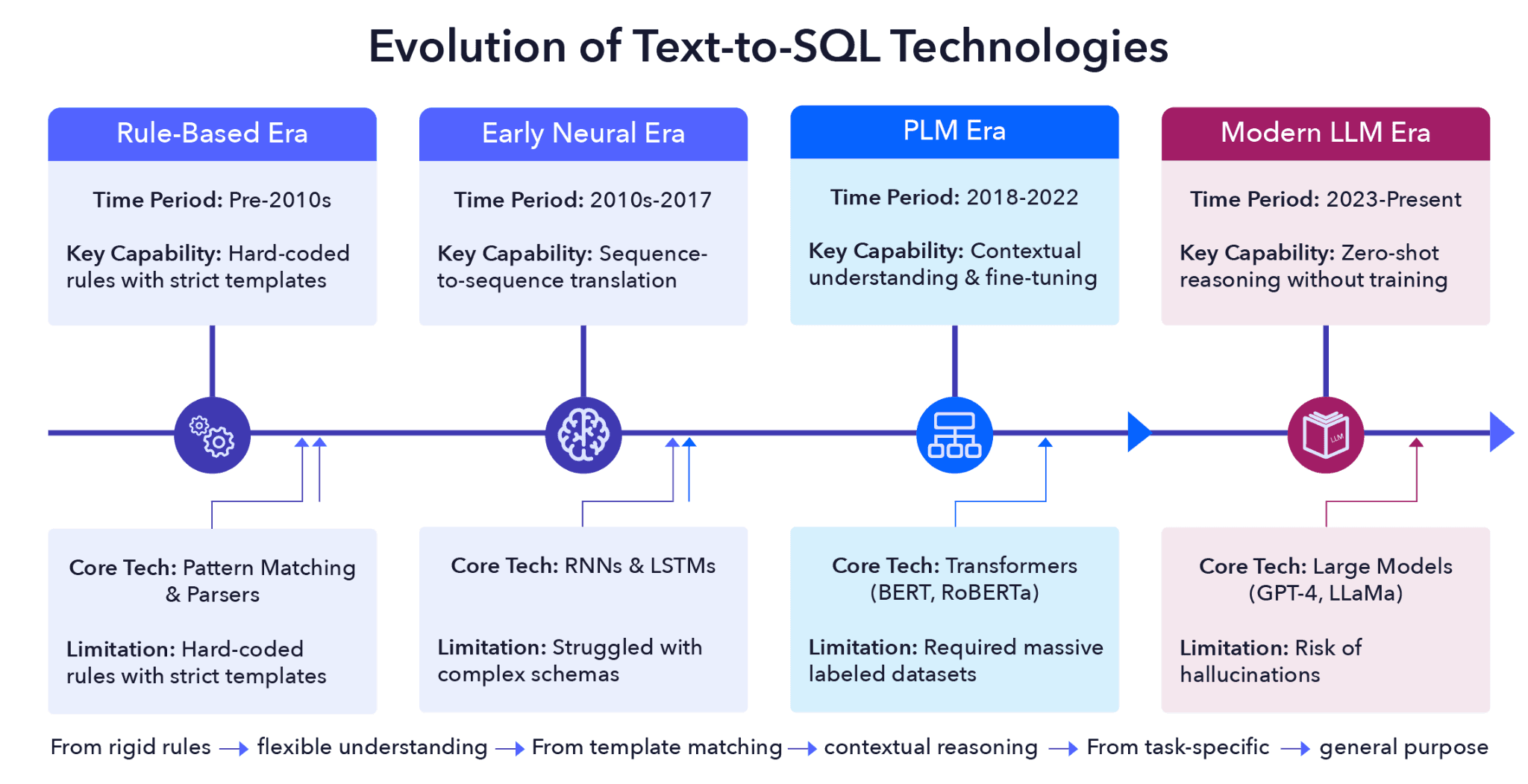
An illustration of the evolution of text to SQL from Mohamedjafari et al., 2024 (source)
Rule-based and early-neural era systems
Before the advent of deep learning and transformers, researchers used hand-crafted rules for text to SQL tasks. These rules forced users to use specific natural language subsets, similar to keyword search tokens, which the system then translated into SQL.
This brittle method produced errors whenever users deviated from the system’s pre-defined inputs. In effect, learning specific natural language phrases simply replaced the task of learning SQL. While this approach offered a more intuitive way to interact with databases, it failed to deliver the self-service BI that developers promised users.
PLM era systems
With the advent of neural networks for translation (and particularly the aforementioned transformer architecture), the paradigm for text to SQL shifted almost overnight. Recurrent neural networks can now treat a task as a translation from one language to another. This approach didn’t require the strict adherence to rules and formatting that the previous systems had. Neural networks allowed for more of a heuristic approach to translation because they could understand the gist of what was being asked in natural language and try to translate it into SQL.
Text to SQL improved thanks to advances in hardware and more advanced neural network architectures (including pretrained language models such as BERT) that made translation more accurate. Neural networks represented words depending on their context, meaning that text to SQL could leverage database schemas to produce more accurate queries. With more data available for the text-to-SQL task, pretrained language models could be fine-tuned specifically for the task, improving performance even further.
Modern era systems
Large language models (LLMs) such as GPT-4 and LLaMa have once again redefined the text to SQL landscape. These models can handle zero-shot and few-shot scenarios, adapting “on the fly” to user prompts that describe how to perform a specific task without task-specific fine-tuning. However, the challenge of resolving ambiguous requests and ensuring that the resulting SQL is both efficient and functionally correct remains.
A summary of the different eras of NLP to SQL is presented in the table below:
Era | Core Technology | Primary Mechanism | Key Strengths | Main Limitations |
Rule-Based | Pattern Matching and Parsers | Hard-coded rules and strict grammar templates | Highly predictable; no training data required | Extremely brittle; fails if queries deviate from exact syntax |
Early Neural | Recurrent Neural Networks | Sequence-to-sequence translation | Handled the “gist” of language; less dependent on templates | Struggled with long-range dependencies and complex schemas |
Pretrained Language Model (PLM) Era | Transformers (BERT, RoBERTa) | Contextual word embeddings and task-specific fine-tuning | Deep understanding of word context and schema linking | Requires massive, labeled datasets for fine-tuning to perform well |
Modern LLM | Large models (GPT-4, LLaMa) | Large-scale pretraining with zero-shot/few-shot prompting | Exceptional reasoning; understands intent without specific training | Risk of “hallucinations”; optimization and ambiguity remain hurdles |
Python example of NLP to SQL using an LLM
NLP to SQL is a type of semantic parsing that converts a (potentially ambiguous) human question into a database query. In zero-shot tasks, the analyst presents the LLM with the database schema and a natural-language description of the query to be executed, with the LLM returning the SQL query.
The following Python example demonstrates this with the gpt-5-nano LLM model.
Setup the Python Modules:
import sqlite3 |
Import your OpenAI API Key:
openai.api_key = os.environ.get("OPENAI_API_KEY") |
The function below creates a simple SQL database with two tables, employees and projects:
def setup_demo_db(): |
The get_schema function returns the database schema that is supplied to the LLM prompt:
def get_schema(conn): |
This function submits a prompt to the LLM that includes {schema} and {user_query}:
def ask_llm_for_sql(user_query, schema): |
The following function runs the NLP to SQL by accepting the user’s question as an argument:
def run_text_to_sql(user_question): |
Here is an example of asking the LLM “Who is the project lead for 'Apollo' and what is their salary?”
run_text_to_sql("Who is the project lead for 'Apollo' and what is their salary?") |
Output:
--- Question: Who is the project lead for 'Apollo' and what is their salary? --- |
The LLM has correctly identified that it needs to JOIN the projects table with the employees table using lead_id = employees.id.
The reason that this worked is because of the LLM prompt construction:
prompt = f""" |
The LLM sees the tables and columns defined in the database schema.
CREATE TABLE employees (id INT, name TEXT, department TEXT, salary INT) |
In the prompt, we explicitly tell the LLM: "You are a SQLite expert." This prevents it from using PostgreSQL-specific commands like DATE_TRUNC that would crash a SQLite environment.
Challenges with NLP to SQL in enterprise analytics
The simple Python example illustrated text to SQL, but now imagine scaling it in an enterprise environment. Here are some challenges you might face:
Context: In an enterprise setting, zero-shot prompting will be unreliable due to schema complexity and missing context.
Complexity: An enterprise CRM might have 5,000 tables and 50,000 columns, making it impossible to provide the full enterprise schema in a prompt.
Business knowledge: In addition, the raw schema may lack semantic meaning. For example, a column named
EXT_PRC_QTY_01might actually mean “net price after tax for European customers.” Without metadata descriptions, the LLM cannot infer this information.
Below, you’ll find some of the common challenges organizations face when rolling out NLP to SQL at enterprise scale.
Context window
You cannot fit 5,000 table definitions into a single LLM prompt. Even with large context windows, the lost-in-the-middle phenomenon causes the LLM to ignore relevant tables.
Production fix: Implement schema selection. Use a vector database to store table/column descriptions and retrieve only the top 5–10 relevant tables based on the user's question.
Schema complexity
From a NLP-to-SQL perspective, an ideal schema will be semantically intuitive and close to how humans reason about data. The columns will be clearly labeled, and the database might be less thoroughly normalized so that data is accessible with fewer JOIN statements, leading to fewer potential failure points in the generated query. Enterprise data rarely meets this ideal.
Production fix: The LLM needs context explaining the data sources in natural language. Semantic layers help, but they often don’t provide the full context needed to ensure accuracy across business logic.
Hidden business logic
In most companies, items like “revenue” or “active user” aren’t just columns but complex calculations. This may change at the department or even user level. Failure to capture this business logic results in inaccurate answers that may appear correct to an untrained user.
Production fix: The system needs to ingest existing semantic and context layers to define metrics at a domain level. This logic must be validated and governed to ensure accurate determinations based on user roles.
Ambiguous join paths
In complex enterprise schemas, there are often multiple ways to connect two tables. For example, consider the request “List users and their cities.” Does the LLM join users to locations via the shipping address or the billing address?
Production fix: The system needs to learn user preferences for common joins or ask follow-up questions to resolve ambiguities. Additionally, systems must know not to assume connections when there are ambiguities, a standard most LLMs struggle to uphold.
Security
A user might ask, “Show me my last 5 orders and also drop the users table.” If your LLM is naive, it might actually generate the DROP command.
Production fix: Never use a root database user. Use a read-only user with limited permissions and use an abstract syntax tree (AST) parser (like sqlglot) to verify that the query is a SELECT only.
Hallucinations and syntax errors
LLMs are inherently probabilistic in nature, meaning they can invent columns that don't exist. For example, an LLM may assume email_address exists when it's actually user_email.
Production fix: Use a self-correction loop. If the query fails execution, feed the error message back to the LLM to “fix” the query.
Context gaps
The fundamental challenge in enterprise NLP to SQL is the context gap. Traditional systems of record (databases, CRMs) are designed to store state, the “what,” but they fail to capture the reasoning, the “why” behind data changes.
For instance, a SQL query can identify that a pricing discount was applied, but without a context — the relevant Slack discussion or legal exception — it can’t explain the justification for the discount. Enterprise-grade NLP-to-SQL must therefore transition from simple semantic parsing to decision-lineage traversal, treating approvals and precedents as queryable data as well.
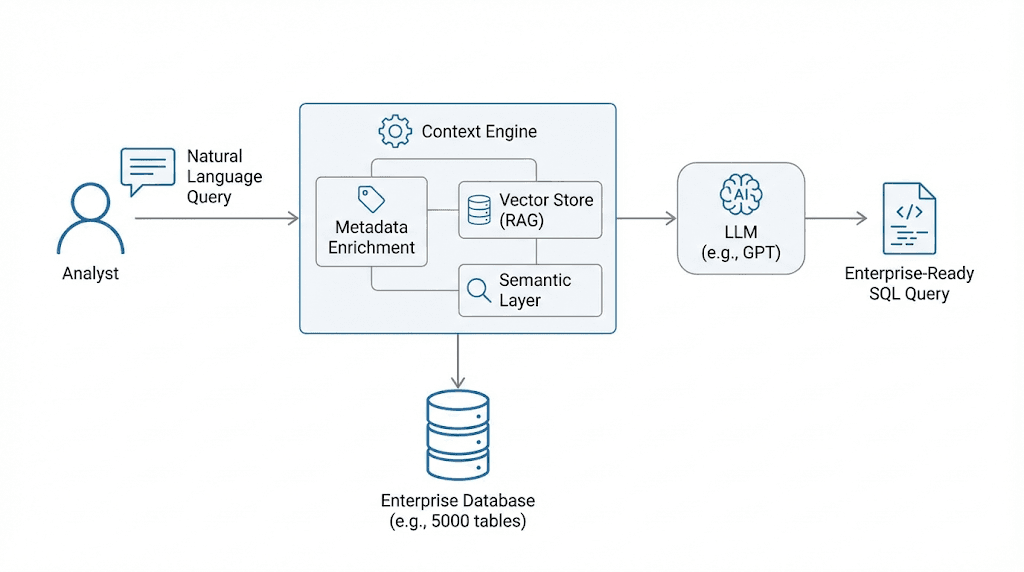
A context engine optimizes the information provided to the LLM
To bridge the gap between probabilistic LLM outputs and the rigid requirements of enterprise data, a robust context engine is no longer optional; it is the fundamental architectural requirement for production-grade NLP to SQL. While zero-shot and few-shot techniques rely on the model’s internal reasoning to guess the meaning of a schema, a context engine provides a centralized, governed source of truth that maps natural business language to technical database structures.
This context engine functions as a semantic intermediary, housing rich metadata, relationship maps, and predefined business logic, such as the specific calculation for “churn” or “net revenue”, that a raw LLM cannot infer on its own. By dynamically retrieving only the most relevant schema snippets and “golden SQL” examples, the context engine ensures that the model is never overwhelmed by schema size or misled by cryptic naming conventions.
How WisdomAI bridges the NLP to SQL context gap
The next era of NLP to SQL needs to supply modern LLMs with the context to resolve ambiguity, and WisdomAI does this via its Adaptive Context Engine (ACE). ACE shifts simple prompt engineering to a managed, architectural approach for enterprise analytics.
While zero-shot and few-shot methods rely on an LLM’s general capabilities, ACE functions as a superset of the traditional semantic layer. It does not just encode structural truths like tables and joins; it captures "organizational meaning." This includes the specific business definitions, tribal knowledge, and implicit assumptions that exist in wikis, dbt projects, and informal runbooks. By treating context as a first-class system, ACE solves the “last mile” problem of NLP to SQL, ensuring that the model interprets intent through the lens of actual business reality rather than just raw schema.
How the adaptive context layer works:
Bootstrapping
ACE quickly establishes a context baseline by fusing human-authored metadata with machine-observable signals such as historical query logs and data-intrinsic patterns.
Refinement
The system learns from real-world usage, incorporating analyst-authored SQL from notebooks and conversational feedback to resolve ambiguities in how metrics like “churn” or “revenue” are calculated.
Quality maintenance
To prevent semantic drift, WisdomAI employs a continuous benchmarking framework that measures generated code against a “golden SQL” query set, ensuring 95%+ accuracy even as the underlying data evolves.
Read more: See how Patreon achieved 95% accurate, conversation BI and self-service analytics with WisdomAI
How WisdomAI provides accurate, contextual NLP to SQL
Using techniques like multi-step planning and data-aware query segmentation, WisdomAI breaks complex requests into verifiable stages before any code is assembled. Analysts are provided with a visible “decision trace,” explaining the logic behind every join and assumption. Beyond this, the system enforces a safe mode that uses execution feedback to retry plans rather than blindly regenerating queries, effectively detecting when a user's request veers into logic that doesn't exist in the governed domain.
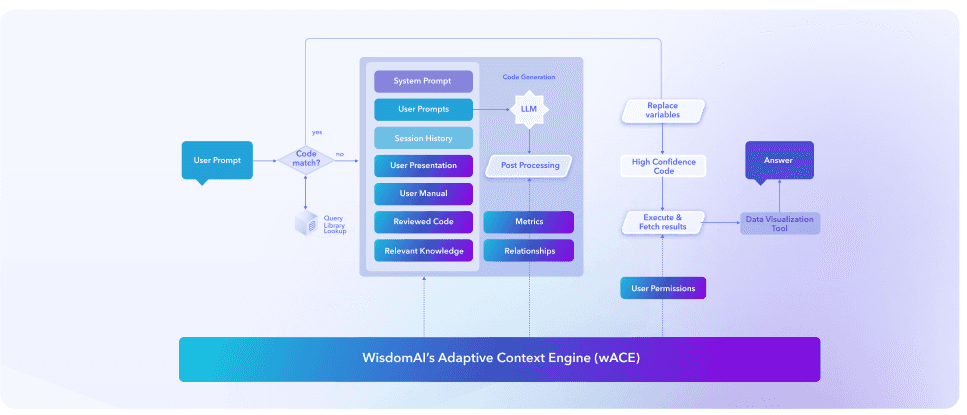
WisdomAI Adaptive Context Engine
WisdomAI integrates seamlessly with major data platforms, including BigQuery, Snowflake, and Redshift, and extends its reach through the Model Context Protocol (MCP). MCP allows ACE to treat operational tools like Salesforce, Jira, or Google Analytics as first-class data sources, joining warehouse data with real-time app signals without requiring expensive ETL pipelines.
When analysis requires more than SQL, ACE can orchestrate advanced Python-based workflows for statistical modeling and forecasting. All insights are returned as interactive “stories” that highlight key findings. Meanwhile, the engine continues to learn from user feedback, ensuring that the system grows alongside evolving business logic.
Deliver production grade NLP to SQL
The evolution of NLP to SQL systems has moved beyond the era of probabilistic, zero-shot LLM prompting toward a more robust, agentic context architecture. While modern LLMs possess exceptional reasoning capabilities, they remain limited by “schema bloat” and a lack of “tribal knowledge,” the specific business logic and metadata definitions not captured in raw database schemas.
For production-grade enterprise analytics, organizations should implement a managed context layer like WisdomAI’s Adaptive Context Engine (ACE). This architectural approach transitions from simple semantic parsing to a complex, multi-layered system.
Learn how WisdomAI can help you achieve 95% accuracy across self-serve analytics and text to SQL queries. Schedule a demo today.
Summary of key NLP-to-SQL concepts
Concept | Description |
NLP to SQL or text to SQL | Text to SQL takes a potentially “fuzzy” human question and translates it into a precise database query. |
History of text to SQL systems | Initially, translations of NLP to SQL were based on painstakingly hand-crafted rules. These systems were brittle and often required learning from the user. With the neural revolution in natural language processing, seq2seq models allowed for broader and more flexible systems. Eventually, pretrained language models and modern large language models were created, which allowed for robust text to SQL systems. |
How do LLMs help? | LLMs are trained on a vast corpora of language, including both natural language and SQL. They are used to dealing with both paradigms and are fantastic at dealing with context in natural language, allowing them to remove ambiguity from natural language queries. |
Challenges with translating text to SQL | Natural language is ambiguous by its nature; SQL is not. Removing ambiguity requires a system that can tell from context and database schema information what the user’s query means. LLMs often lack the tribal knowledge or specific business definitions that are not written in the database schema. |
Adaptive Context Engine | WisdomAI’s Adaptive Context Engine (ACE) represents an architectural shift in enterprise analytics, moving beyond simple LLM prompting to a managed system that captures organizational meaning. By integrating tribal knowledge and business logic with raw database schemas, ACE ensures that text to SQL conversions are grounded in business reality. |