
Unstructured Data Analysis: Providing Context For Structured Data
Why 90% of enterprise data is unstructured—and what that's costing your team
How AI-powered unstructured data analysis reveals what structured data can't
What it takes to analyze documents, tickets, and text alongside your core data
PUBLISHED:
UPDATED:
Your dashboard show a jacket’s return rate spiked to 18% last quarter. But it can’t tell you why. That answer is buried in 4,000 customer reviews, 600 support tickets, and internal Slack threads — none of which fit neatly into a SQL table.Around 90% of all enterprise data falls into this category: unstructured, scattered across business applications, and impossible to analyze with traditional BI tools. For this reason, it’s often referred to as “dark data.”But it’s not as ominous as it sounds. In reality, unstructured data is where you’ll find the most honest signal about your operations and risks. You just need the right tools, methodology and context to analyze it. Use this article as your guide.
What is unstructured data?
Unstructured data is information that does not neatly fit into rows and columns of a structured table. Examples of unstructured data include customer reviews, support tickets, contract PDFs, and product photos.In an enterprise business, a set of unstructured data might look like hundreds of support tickets describing the same issues in different ways, Slack or email threads discussing anomalies, or notes added by analysts to explain sudden changes in performance.These items contrast with structured data, such as revenue or sales tables, return rates, or inventory counts, which follow fixed schemas that fit into tables, making it easy to store, query, aggregate, and feed into KPI dashboards.
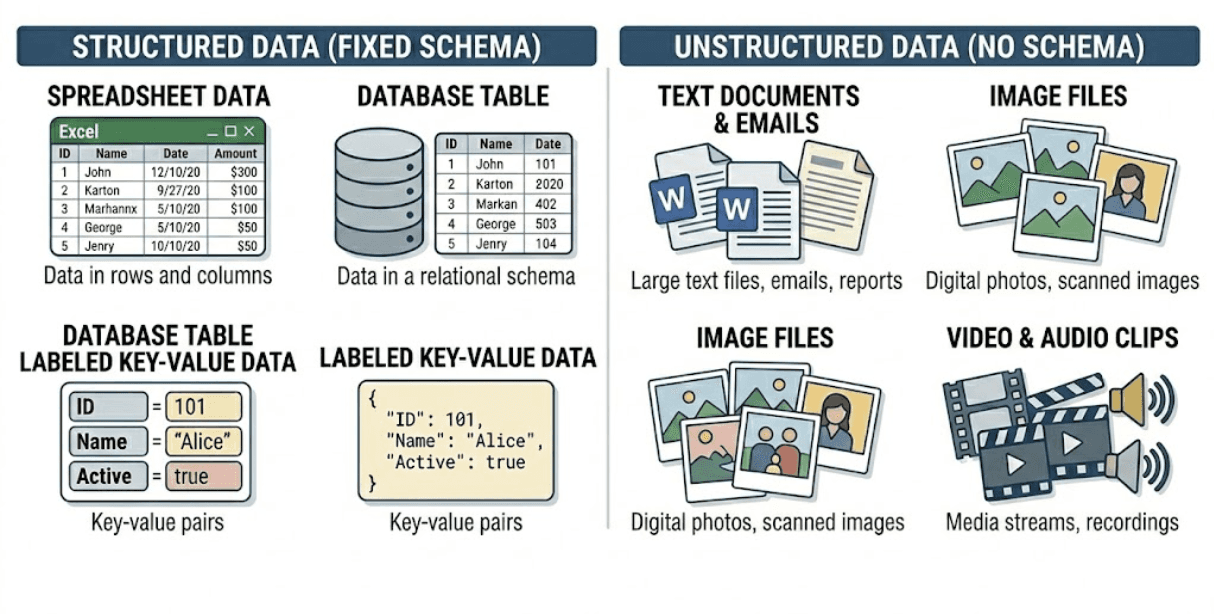
Common examples of structured data (fixed schema) versus unstructured data (no schema)To understand the difference in practice, imagine that an apparel company has a jacket with an unusually high return rate. Structured data, such as sales or return tables, can show you the numbers, tell you that the product is being returned frequently, and show the dates when these returns occur and which regions they come from. However, these tables can’t tell you why the item is being returned, because the reason is often hidden in unstructured data.Customer reviews and support tickets may often mention that sizing runs small, the fit feels uncomfortable, or the product looks different from the photos. These details are exactly what teams need to understand and fix the underlying issue. That’s why structured and unstructured data work best when combined together for business analytics: structured data flags problems, while unstructured data provides the reasoning behind them.The challenge and the opportunity lie in extracting useful information from unstructured data inputs and turning it into signals that can be analyzed alongside traditional structured information.
Feature extraction for unstructured data analysis
Before recent AI advances, unstructured data was treated like a math problem, operating on logic and statistics. One common example of pre-generative AI (GenAI) unstructured data analysis is feature extraction, which allows users to transform raw, unstructured data into organized, numerical data that a machine can understand.Let’s use unstructured textual data as an example: word-count models, like bag of words (BoW), counts the number of times a word appears in a corpus, converting text into numerical representations based on the count of each word. The technique does not understand grammar, order or context; it simply measures how often words appear.Companies can then use these methods for keyword searches, word clouds and basic text counting to identify patterns. For example, a sales leader might use this method to assess common objections that arise in calls. Or, a retail manager might use this unstructured analysis style to calculate sentiment in user-generated reviews. While these methods are easy to implement and computationally efficient at turning unstructured data into something that can be analyzed by traditional BI tools, they often fail to capture the deeper meaning and context within the data. For instance, they cannot detect sarcasm, distinguish context, or understand that “great” and “excellent” express similar meanings. In essence, feature extraction measures text, but it can’t comprehend it.
Feature extraction example in enterprise analytics
Let’s expand on the retail manager example. Imagine that we have three reviews for a specific T-shirt on an ecommerce site as follows:
Review A: “The fabric is soft.”
Review B: “The fabric is not itchy.”
Review C: “Nice color and not itchy at all.”
In BoW, a list of all unique words across all reviews is created:[‘The’, ‘fabric’, ‘is’, ‘soft’, ‘not’, ‘itchy’, ‘nice’, ‘color’, ‘and’, ‘at’, ‘all’]Then, the model counts how many times each word appears in each review:
Review | ‘The’ | ‘fabric’ | ‘is’ | ‘soft’ | ‘not’ | ‘itchy’ | ‘nice’ |
Review A | 1 | 1 | 1 | 1 | 0 | 0 | 0 |
Review B | 1 | 1 | 1 | 0 | 1 | 1 | 0 |
Review C | 0 | 0 | 0 | 0 | 1 | 1 | 1 |
SUM | 2 | 2 | 2 | 1 | 2 | 2 | 1 |
Challenges with text-based feature extraction in data analysis
When someone analyzes these reviews solely by word count, without actually reading them, they might mistakenly conclude that the product is frequently described as “itchy,” signaling a quality issue. If these word-count representations are passed downstream to predictive models, it will introduce misleading signals, classifying the reviews as negative because they are missing vital sentiment context.
How unstructured images and audio were analyzed before generative AI
Before modern neural networks, a similar limitation existed for images and video. These legacy unstructured image analysis systems rely heavily on manually engineered features, like principle component analysis (PCA) to identify objects and count how many times they appear in a set of photos or audio files. Using these methods for visual analysis, engineers must explicitly define which features a model should look for, such as edges, corners, or specific geometric shapes. To detect a car, for instance, the system might search for circular features representing wheels and rectangular patterns representing the body. These handcrafted features are then passed into downstream models as the basis for classification.
Challenges with traditional unstructured data analysis of images and audio
This approach to analyzing unstructured images and audio data sources is extremely brittle. A slight distortion in lighting, perspective, orientation or audio quality can alter the extracted features, leading the system to fail. Because the machine can not truly see or understand the object, it simply checks if the predefined features are present. As a result, feature engineering becomes a bottleneck, making it difficult to build scalable and robust unstructured analysis systems for diverse, real-world enterprise environments. For example, in high-quality manufacturing, a major challenge is that defects are rare, leaving edge cases underrepresented in training data. This data scarcity results in either overfitting to the limited set of defects or underperforming when encountering new types of anomalies. GenAI can overcome data scarcity by generating synthetic defect images.
Semantic embedding methods for unstructured data analysis
Where pre-GenAI approaches treat unstructured data as a feature engineering problem where engineers manually design features (e.g., TF-IDF, n-grams, word counts) that statistical models learn from, modern analytics applications shift this burden to large neural networks. Now, large language models (LLMs) are able to autonomously learn representations during pretraining, freeing engineers to focus on composing the right context through retrieval, prompts, and tools. This AI context is critical to ensuring the model can perform inference over the relevant information. Modern unstructured analysis architecture is built on dense embeddings, hybrid retrieval, rerankers, and LLMs. Combined, they form the core of retrieval-augmented generation (RAG) pipelines: the foundation for analyzing unstructured data at scale in a reliable and auditable way.
The process for analyzing unstructured data in the GenAI era
First, all unstructured data is transformed into vector representations using multimodal embedding models. Text documents, images, and even transcribed audio are converted into numerical vectors that capture semantic meaning. These embeddings are stored in a vector database, allowing the system to search by meaning rather than just keywords.
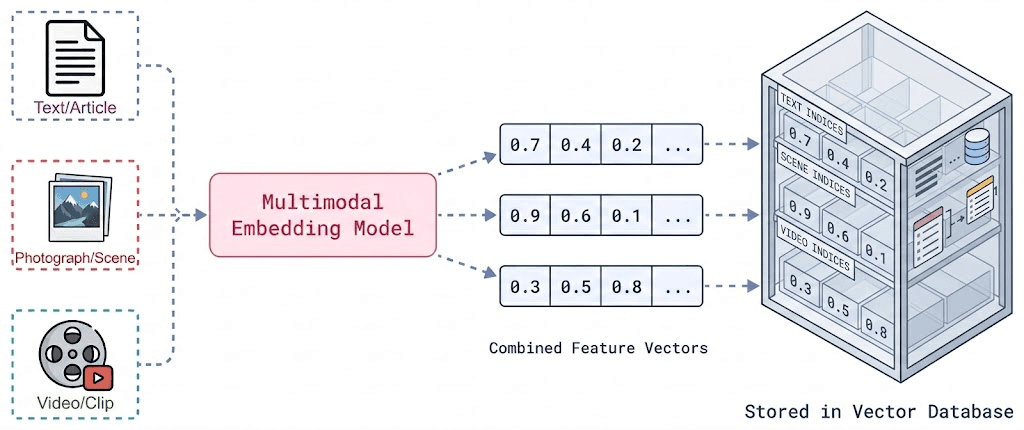
Transforming unstructured data into embedding vectorsSecond, the retrieval of these vectors is done using a hybrid strategy. Vector search retrieves semantically similar vectors, while sparse search (e.g., BM25 or keyword-based search) captures exact key term matches. Combining both methods ensures high accuracy of retrieval — semantic similarity prevents missing contextually related results, and keyword search ensures precision when specific terms matter. In enterprise systems, this retrieval step often runs multiple times, reformulating the query to maximize coverage.Third, a reranker model often evaluates the retrieved data to identify the most semantically similar and useful results. Unlike retrieval in the previous step, which relied on vector similarity scores alone, the reranker reads the query and each retrieved information together, allowing it to deeply assess their relationship. It analyzes how well the meaning of the information aligns with the intent of the query and assigns a refined relevance score. By reranking the retrieved information, only the most contextually appropriate vectors and filters are built into the analysis. This significantly improves the relevance of unstructured data before passing it to the final reasoning model. Finally, the LLM synthesizes an answer based on the provided information.
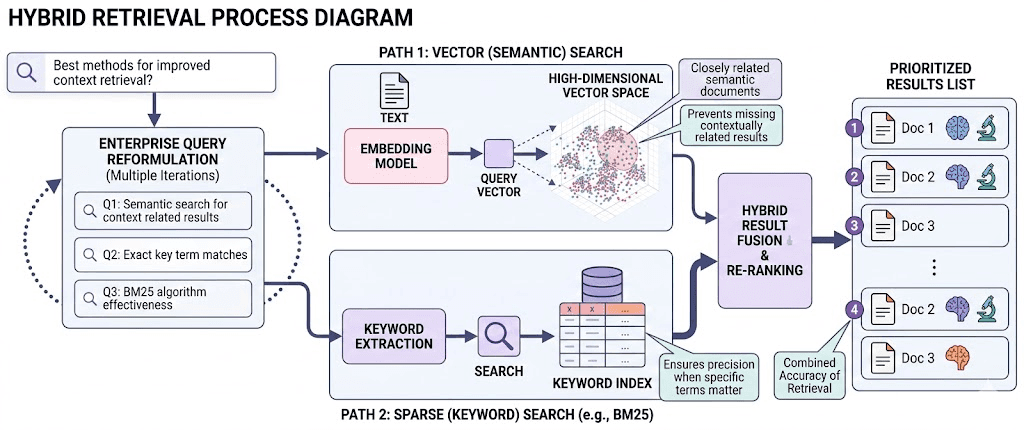
The hybrid retrieval process, combining vector and keyword search for highly accurate resultsInstead of generating responses from general training data, the model is grounded in content from the hybrid retrieval process. This reduces hallucinations and enables citations, making outputs explainable, which is a non-negotiable requirement in real-world enterprise systems.
Example of unstructured data analysis using RAG
Let’s observe a real scenario of how a merchandiser might analyze unstructured customer reviews using a modern RAG-driven system. The customer reviews are first converted into dense vector embeddings and stored in a vector database. When someone asks, “What are customers saying about the fit and fabric of X product?” the system does not rely on simple word matching. Instead, it performs hybrid retrieval to find reviews that align with the query. First, the question itself is transformed into a dense embedding using the same embedding model that was used to vectorize all customer reviews. This query vector represents the intent behind the question — not just words like “fit” and “fabric” but related concepts such as sizing accuracy, tightness, looseness, comfort, material quality, softness, thickness, breathability, and texture. The vector database then performs semantic retrieval to find the reviews whose embeddings are closest or similar to the query embedding.At the same time, another retrieval method, usually based on a classical bag-of-words algorithm like TF-IDF, runs in parallel to capture exact term matches. This hybrid retrieval strategy ensures both contextual understanding and precision. Reviews mentioning specific phrases like “runs small,” “tight around the shoulders” or “material feels soft but thin” are retrieved, even if they do not explicitly use the words in the original query. Next, a reranker model evaluates the retrieved reviews by reading each review together with the original question. The reranker deeply assesses how well each review aligns with the user’s intent and assigns refined relevance scores. Weak or loosely related matches are filtered out, and the most contextually appropriate reviews are promoted.Finally, only the highest-quality reviews are passed to the LLM, which is then asked to perform a structured analysis. The LLM model can be instructed to extract specific aspects (such as fabric and fit), determine the sentiment associated with each sentiment, and return structured output that includes references to the original review IDs for full traceability. The output is clear and easy to understand. For example:
Fabric: Positive (based on reviews R1 and R3)
Fit/sizing: Negative (based on review R2)
Each insight is directly backed by real customer reviews, so you can clearly see what customers liked or disliked and exactly which feedback supports that conclusion.
Example of LLMs generating structure from unstructured data
Let’s consider the merchandising manager reviews example again:“The material feels premium but it runs small around the shoulders.”On its own, this is qualitative feedback. But when processed by an LLM with structured extraction instructions, it can be converted into an analyzable dataset. The information from this unstructured review above can be stored in a structured table, as follows:
Review_ID | Product_ID | Aspect | Sentiment | Evidence_Text |
R4012 | JKT-8871 | Fabric | Positive | “Material feels premium” |
R4012 | JKT-8871 | Fit | Negative | “Runs small around the shoulders” |
When scaled across thousands of reviews, this becomes a structured sentiment table. Analysts can now compute the percentage of each sentiment by product, find correlation between complaints and return rates, and unlock sentiment trends before and after design updates. What was once scattered text is now a core part of the modern BI environment.
Benefits of modern unstructured data analysis techniques
In advanced enterprise environments, LLMs are increasingly used as transformation engines. They ingest raw content such as reviews, support tickets, PDFs, or images and output JSON structures that can be put into schema-aligned tables. In other words, unstructured data becomes a structured analytical asset.This data can then be combined with your other structured data sources, providing deeper understanding of key drivers within your business. When teams can chat with their data and use agentic analytics to trigger analysis, you can spot and solve issues before they impact your bottom line. You can also use this hybrid approach to find opportunities for savings, differentiation, and growth. For example, a procurement team at a global B2B tech company was able to combine critical contract language that lived in PDFs and spreadsheets with their ERP data to get a more complete picture of their supplier contracts. Using Wisdom.AI’s chat interface, the team was able to ask questions like, “which suppliers have renewal clauses expiring this quarter with above-benchmark pricing?” and get a real answer, immediately. As a result, they saved over $50M in just one year of contract negotiations.
How to analyze unstructured data in WisdomAI’s Adaptive Context Engine
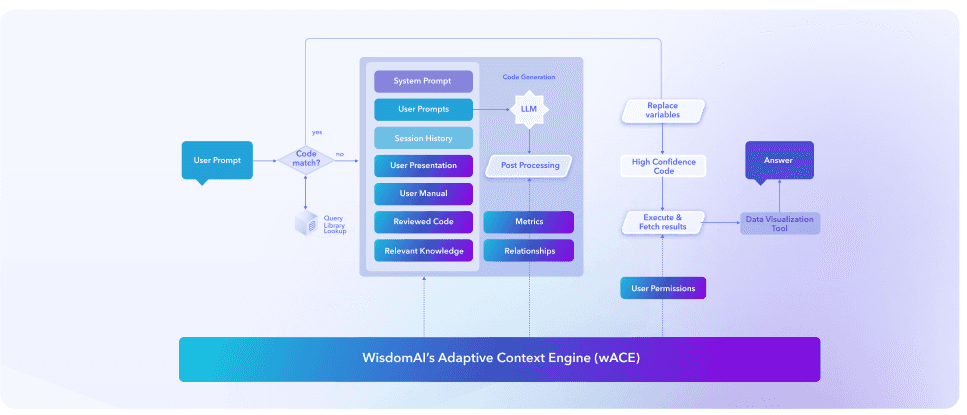
The WisdomAI Adaptive Context Engine (ACE) serves as a foundational intelligence layer that bridges the gap between raw, unstructured data and reliable, actionable insights. With the context layer running in the background, non-technical users can ask and answer natural-language questions, retrieving contextually-rich answers that empower impactful, real-time decision making. Unlike traditional static databases, WisdomAI domains function as a business memory system for large language models, capturing the semantic relationships between business knowledge and raw, unstructured datasets, like dbt YAML, LookML, PDFs, text files, or query logs. ACE analyzes these unstructured sources to propose table/column descriptions, metric definitions, join logic, business context rules, and example question-to-SQL pairs. Data teams then employ a human-in-the-loop check, codifying context into the domain. As a result, ACE ensures LLMs understand the nuanced intent behind a search before generating a query to retrieve structured data, improving the accuracy and business impact of all subsequent analyses.
How ACE bridges the context gap
WisdomAI standardizes definitions, connects fragmented data sources, and preserves the relationships between entities, metrics, and time. Every query is enriched with this shared business context, transforming siloed information into a unified knowledge layer that:
Reduces hallucinations: Ensures outputs are grounded in evidence.
Deciphers intent: Uses unstructured context to translate “human” questions into precise data queries.
Maps relationships: Links qualitative themes and sentiment directly to quantitative business metrics.
WisdomAI Adaptive Context Engine
Real-World Impact: Turning “What” into “Why”
WisdomAI enables teams to go beyond descriptive data analytics. For example, if a merchandising manager notices that a shirt’s return rate (structured data) increases, they might ask WisdomAI’s chat interface, “Why did the return rate on this shirt increase?”
Core analysis
WisdomAI will run an analysis to identify the SKU, determine the time frame for the return increase, and identify all relevant data it can analyze for more information.
Unstructured analysis
Using deep analysis, the system will review any relevant data in the Domain, including unstructured data, such as customer reviews stating “fits too tight,” and support tickets regarding exchanges. WisdomAI can then correlate the timeline of those reviews with your ERP data, showing that the manufacturer changed during that time.
Natural language answer
As a result, the user will receive the natural language answer back in their chat interface, explaining that the manufacturing change is likely the cause of the spike in shirt return rates.
Web-sourced recommendations
If the user replies asking for recommendations on how to resolve the issue, WisdomAI analyzes past-supplier issue resolution patterns available in the ERP and sources recommendations from the web, surfacing recommended actions in the original chat thread.
Human-in-the-loop
Throughout the analysis, the user can see the full reasoning logic and supporting SQL queries to fact-check the analysis and understand the recommendation before taking action.
Automated agentic
Using WisdomAI’s agentic feature, the retail manager could build a workflow that periodically checks for spiked returns across their SKUs, proactively alerting the team to take action before they even know to look.As demonstrated in this example, WisdomAI helps teams across the business immediately understand the root cause instead of manually piecing together fragmented spreadsheets. The platform continuously surfaces emerging trends and anomalies in real time. Instead of navigating static dashboards, users engage in an ongoing dialogue with their data, leveraging a persistent, evolving business memory to uncover not just what is happening, but exactly why it is happening. With advanced reasoning and agentic workflows, your business can move from reactive reporting to proactive intelligence.
Turn unstructured data into game-changing insights
With modern AI architecture, users across your businesses can now unlock the value of unstructured data in ways previously inaccessible. You are no longer limited to surface-level keyword counting or rigid, manually engineered features. With the right technology, you can leverage semantic reasoning to uncover the deep “why” behind business metrics, and even start answering “what next?”While many LLMs are capable of deep reasoning on unstructured data sources, most lack the context to connect data across your business. Context is the only way to convert these insights into actionable, reliable advice. WisdomAI’s Adaptive Context Engine turns your siloed business data into a unified, searchable knowledge base, giving you the ability to convert unstructured noise into structured signals.
It’s time to turn your data into your competitive advantage. See how WisdomAI can help. Schedule a demo today.
Summary of key unstructured data analysis concepts
Concept | Description |
Unstructured data | Unstructured data refers to information that does not conform to predefined schemas, such as text, images, audio, or video. It is rich in context but difficult to store, query, and analyze using traditional database systems. |
Feature extraction methods for unstructured data analysis | Traditional approaches (e.g., Bag of Words or TF-IDF) convert unstructured data into numerical features by counting word occurrences, enabling basic pattern detection without understanding context or meaning. |
Feature extraction enterprise example | In enterprise settings, unstructured data was historically processed using keyword-based methods, rule-based systems, and simple statistical techniques to categorize and organize information. |
Semantic embedding methods for unstructured data analysis | Modern AI approaches, such as retrieval-augmented generation (RAG), use embeddings, hybrid retrieval, and large language models to semantically understand and transform unstructured data into structured, analyzable outputs. |
Semantic embedding methods enterprise example | In modern systems, unstructured data is converted into vector embeddings and stored in vector databases, enabling retrieval based on semantic similarity and powering context-aware analysis instead of relying solely on keyword matching. |
WisdomAI Adaptive Context Engine | The WisdomAI Adaptive Context Engine acts as a business memory layer that connects unstructured and structured data by preserving relationships among entities, metrics, and time. It enriches every query with shared business context, enabling accurate, explainable insights and linking qualitative signals directly to quantitative outcomes. |
